Learning Synergies between Pushing and Grasping
with Self-supervised Deep Reinforcement Learning
Skilled robotic manipulation benefits from complex synergies between non-prehensile (e.g. pushing) and prehensile (e.g. grasping) actions: pushing can help rearrange cluttered objects to make space for arms and fingers; likewise, grasping can help displace objects to make pushing movements more precise and collision-free. In this work, we demonstrate that it is possible to discover and learn these synergies from scratch through model-free deep reinforcement learning. Our method involves training two fully convolutional networks that map from visual observations to actions: one infers the utility of pushes for a dense pixel-wise sampling of end effector orientations and locations, while the other does the same for grasping. Both networks are trained jointly in a Q-learning framework and are entirely self-supervised by trial and error, where rewards are provided from successful grasps. In this way, our policy learns pushing motions that enable future grasps, while learning grasps that can leverage past pushes. During picking experiments in both simulation and real-world scenarios, we find that our system quickly learns complex behaviors amid challenging cases of clutter, and achieves better grasping success rates and picking efficiencies than baseline alternatives after only a few hours of training. We further demonstrate that our method is capable of generalizing to novel objects.

The images on the left show an example configuration of tightly packed blocks reflecting the kind of clutter that commonly appears in real-world scenarios (e.g. with stacks of books, boxes, etc.), which remains challenging for grasping-only manipulation algorithms. Our system is able to plan pushing motions that can isolate these objects from each other, making them easier to grasp; improving the overall stability and efficiency of picking. The video on the right shows a live demo, where three blocks are laid in an arrangement (not seen in training) that is too wide to grasped together directly. So the robot plans a sequence of pushes to separate the objects from each other, allowing them to be grasped individually. These skills emerge naturally from learning, trained from trial and error via self-supervision.
Latest version (27 Mar 2018): arXiv:1803.09956 [cs.RO] or here.
To appear at IEEE International Conference on Intelligent Robots and Systems (IROS) 2018
★ Best Cognitive Robotics Paper Award Finalist, IROS ★







Code
Code is available on Github. Includes:- Training/testing code (with PyTorch/Python)
- Simulation environments (with V-REP)
- Code for real-world setups (with UR5 robots)
- Pre-trained models and baselines
- Evaluation code (with Python)
Bibtex
@article{zeng2018learning,
title={Learning Synergies between Pushing and Grasping with Self-supervised Deep Reinforcement Learning},
author={Zeng, Andy and Song, Shuran and Welker, Stefan and Lee, Johnny and Rodriguez, Alberto and Funkhouser, Thomas},
booktitle={Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IROS)},
year={2018}
}Summary Video
Method: Visual Pushing and Grasping (VPG)
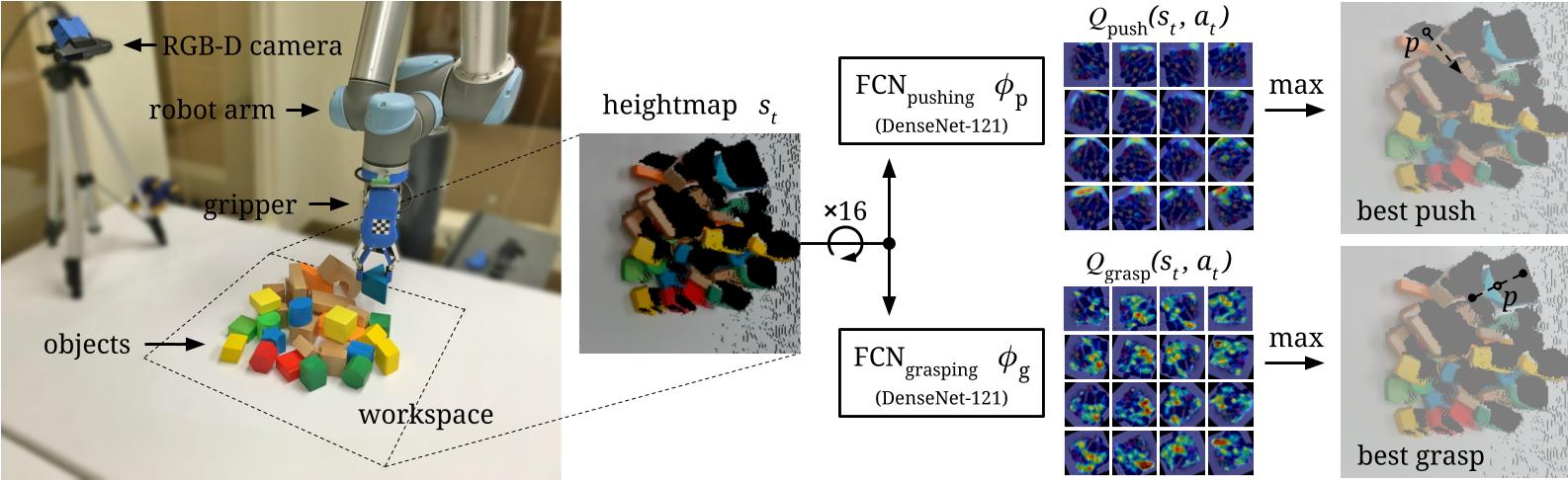
Here is an overview of our system and Q-learning formulation. Our robot arm operates over a workspace observed by a statically mounted RGB-D camera. Visual 3D point cloud data is re-projected onto an orthographic RGB-D heightmap, which serves as a representation of the current state st . The heightmaps are then fed into two FCNs - one Φp inferring pixel-wise Q values (visualized with heat maps) for pushing to the right of the heightmap and another Φg for horizontal grasping over the heightmap. Each pixel p maps to a different 3D location on which to execute the primitive: for pushing, this location represents the starting position of the pushing motion; for grasping, the middle position between the two fingers during parallel-jaw grasping. The FCN forward passes are repeated for 16 different rotations of the heightmap to account for various pushing directions and grasping orientations. These FCNs jointly define our deep Q function and are trained simultaneously from scratch. The system is entirely self-supervised through trial and error, where rewards are provided from successful grasps. Our method is sample efficient - we are able to train effective pushing and grasping policies in less than 2000 transitions. At 10 seconds per action execution on a real robot, this amounts to about 5.5 hours of wall-clock training time.
Example Results: Picking
Visual Pushing and Grasping (VPG) on several unseen test cases with challenging clutter (real-world and simulation):
Total # of actions: 7 (task complete)
Total # of actions: 7 (task complete)
Total # of actions: 10 (task complete)
Total # of actions: 10 (task complete)
Note: the extra isolated yellow/red blocks serve as a sanity check to ensure that all policies have been sufficiently trained prior to the benchmark (i.e. a policy is not ready if fails to grasp the isolated object).
Across all of our experiments, VPG is consistently more efficient at picking than grasping-only policies, which demonstrates that pushing enlarges the set of scenarios in which grasping succeeds. For comparison, below are several examples of grasping-only policies on the same test cases shown above:
Total # of actions: N/A (task incomplete)
Total # of actions: 15 (task complete)
Total # of actions: 13 (task complete)
Total # of actions: N/A (task incomplete)
VPG also works on novel objects (unseen during training):
For more quantitative evaluations and ablation studies (in both simulation and real-world settings), please check out our technical report. There, we also explore some interesting questions like:
- Is it possible to train pushing policies without any rewards? Can intrinsic rewards help?
- Does long-term lookahead matter for planning VPG strategies in picking?
- Is it possible to train VPG policies without ImageNet pre-training? How much do pre-trained weights influence sample complexity and performance?
- Can we train VPG policies with only color information (no depth/height-from-bottom information)?
Failure Modes
A common failure case of VPG during testing includes excessively pushing everything (out of view) as grasping Q values remain low. This occurs most frequently with novel objects, or objects too large to grasp.
Contact
If you have any questions, please feel free to contact Andy Zeng
Tuesday, March 28, 2018
Posted by Andy Zeng